学习笔记——《Professional CUDA C Programming》Ch1 Heterogeneous Parallel Computing With CUDA
Ch1. Heterogeneous Parallel Computing With CUDA
前言
本系列笔记是《Professional CUDA C Programming》的读书笔记,基本顺序与书的目录相一致,总结了其中我认为重要的知识点,以及通过查阅相关技术资料加入了我个人的理解。文中部分内容引用原书中的图、文字和表述,均会在旁边加以标注。

并行计算概述
并行计算是当今技术飞速发展的重要推动力,是实现高性能计算(HPC, high-performance computing)的核心技术之一。近年来,CPU-GPU 异构架构(heterogeneous architecture)将并行计算的发展提升到了一个新的高度。通常来说,并行计算可以分为两个维度:
- 硬件方面:计算架构 (Computer architecture)
- 软件方面:并行编程 (Parallel programming)
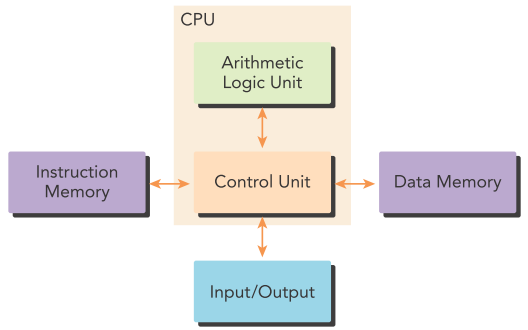
现代CPU多采用Harvard架构:
并行计算通常分为两种:
- 任务并行(Task parallelism)
- 数据并行(Data parallelism) => CUDA 编程
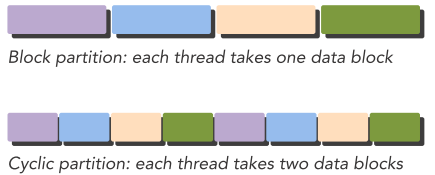
数据并行的一个首要任务是数据分配(Data partitioning),包括block partitioning 和cyclic partitioning。选择何种分配方式需要考虑程序本身设计以及硬件架构的信息,选择最优的block size和分配方式。
计算架构的分类
计算架构可分为四类:
- 单指令流单数据流:Single Instruction Single Data (SISD) => 传统单核电脑
- 单指令流多数据流:Single Instruction Multiple Data (SIMD) => 多核电脑,Vector向量机
- 多指令流单数据流:Multiple Instruction Single Data (MISD) => 少见
- 多指令流多数据流:Multiple Instruction Multiple Data (MIMD) => 多核处理多路数据,最强并行性
在架构设计层面,有三个最重要的优化指标:
- 低延迟(low latency):单次操作所花费的时间,通常用s或ms衡量。
- 高带宽(high bandwidth):单位时间内处理的数据量,通常用MB/s或GB/s衡量。
- 高吞吐(high throughput):单位时间内处理的操作量,通常用gflops衡量(billion floating-point operations per second)。(值得注意的是,低延迟并不一定意味着高吞吐,二者之间的关系还与系统的并行性有关。有关延迟和吞吐量的理解,可以参考:如何理解Latency和Throughput: 吞吐量和延迟 - Binyao - 博客园 (cnblogs.com))
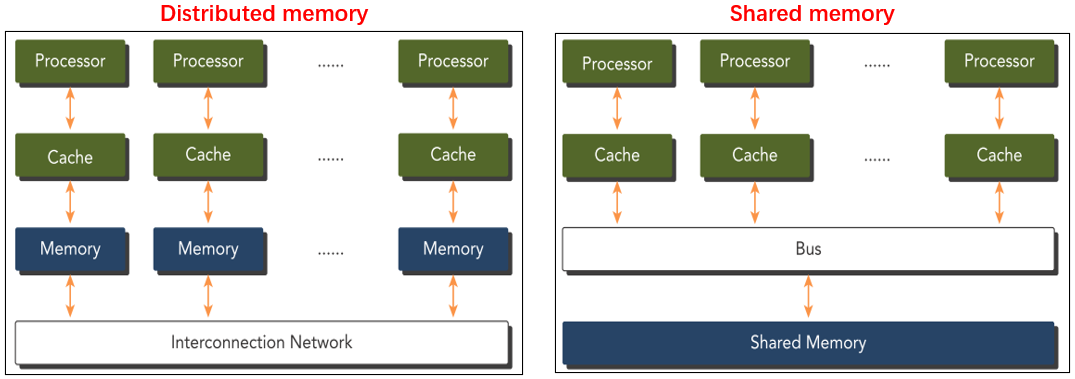
多核系统的内存分配方式有独立(distributed)和共享(shared)两种。
GPU的设计架构非常适合于并行计算:多核心、多线性、MIMD、SIMD、并行指令集等。NVIDIA将其架构命名为SIMT(Single Instruction, Multiple Thread)。GPU核心和CPU核心的区别在于:CPU核心结构复杂,适用于复杂的逻辑计算,目标是对顺序执行的程序进行优化;而GPU核心结构简单,适用于简单逻辑下大量数据的并行计算,目标是提高并行程序的吞吐量。
异构架构
CPU适合处理逻辑集中型(control-intensive)任务,GPU适合处理数据集中型(data-parallel computation-intensive)任务,将CPU和GPU各自的优势相结合,就得到了异构架构(Heterogeneous Architecture)。在异构架构中,CPU被称为Host,GPU被称为Device。CPU上运行的Host代码主要用来配置环境、调用程序、准备数据以及一系列复杂操作为数据密集型计算作好准备,而GPU上运行的Device代码则专门针对大量集中的数据操作进行并行加速计算。在该架构中,CPU作为逻辑中枢,控制整个任务的启动、执行与终止,GPU作为计算中枢,专门对大量数据进行集中处理,二者之间通过PCIe总线进行通信。
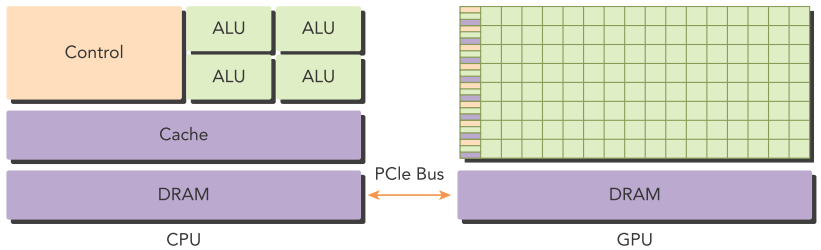
CPU和GPU的特性如下图。CPU的单核性能非常强大,能处理极其复杂的逻辑运算,但是核的数量相对较少(例如现在典型的16核32线程(超线程)CPU,参考 CPU工作方式、多核心、超线程技术详解 - 知乎 (zhihu.com));而GPU单核性能简单,只能处理简单的计算任务,但是每个核的线程数非常多(典型的16核GPU可能支持几万到几十万个线程)。当任务的数据量较小、执行逻辑复杂、由大量短小的串行操作组成、需要处理无法预知的控制流、多任务并行等场景时,建议使用CPU,例如文字处理、表格计算、视频编辑等。当任务的数据量庞大、每条数据的处理逻辑相对简单时,建议使用GPU,例如深度学习计算、图形渲染、视频解码等。
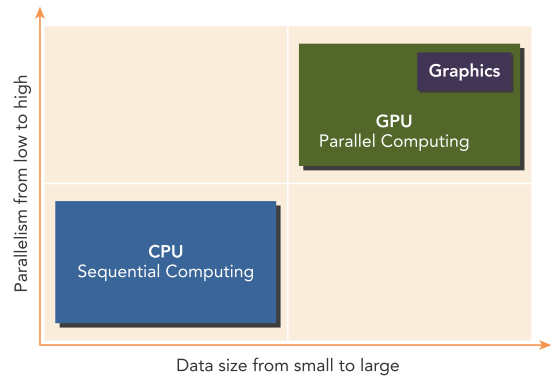
这里插一个小问题:为什么CPU的超线程通常是单核双线程,而GPU可以做到单核成千上万个线程?原因如下:
- GPU的硬件架构不同于CPU,GPU采用了大量简化的并行计算核心架构,每个算核支持同时执行多个线程。而CPU计算核心设计注重单线程性能。
- GPU每个算核只支持基本的 Arithmetic logic unit (ALU)运算,没有复杂的流水线和指令调度能力。这使得GPU算核对线程切换开销小,可以支持更多线程。
- GPU算法用到的线程通常是重复独立执行同一任务的临时线程,不涉及复杂同步和通信。这种轻量级的线程更利于大规模并行。
- CPU针对各种通用应用,需要兼顾单线程完整运算能力,增加了核心复杂度。GPU针对专用计算,可以进行更深层的简化优化。
- GPU可以利用大量工作单元并行运算不同任务不同片段,隐藏寄存器和内存等访问延迟。而CPU需要在同一时钟内完成指令执行。
- GPU适用于数据驱动型并行计算,每个线程负责独立可重复的片段运算,规模化效应更明显。
在使用异构架构处理具体的任务时,如何根据任务的特点优化Host和Device代码以充分发挥CPU和GPU各自的特点,二者优势互补相辅相成,实现高效计算,是异构架构编程的核心。异构编程不仅要求编程者在对于CPU和GPU的代码层面熟练掌握,而且还需要具备一定的底层硬件、网络通信等知识,并且要针对不同的具体任务制定最佳的编程策略,以最大限度地利用系统资源进行高效计算。为此,NVIDIA为开发者们提供了一套成熟的异构编程模型——CUDA。
CUDA: 异构计算编程平台
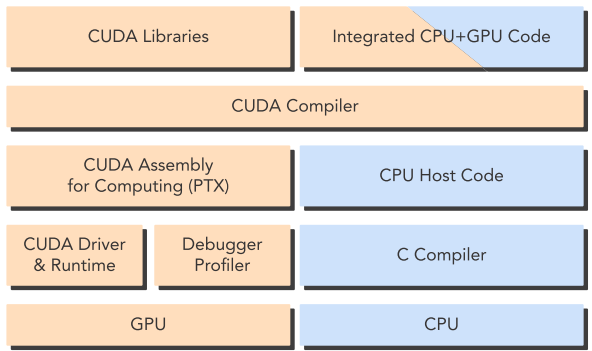
CUDA是NVIDIA提供的、为通用并行计算目标、提供一系列编程模型的高效的开发平台。使用CUDA编写代码可以在CPU中方便地调用GPU进行计算,并且与经典的CPU代码编程语言高度相似,例如CUDA C/C++/Python等,帮助传统的CPU平台开发者能以很低的学习成本迅速熟悉并掌握并行计算的开发。CUDA提供了不同硬件硬件层面的库和API,从上到下分别为:应用层、CUDA Libraries、CUDA Runtime、CUDA Driver、硬件层。本书使用的是CUDA C语言。
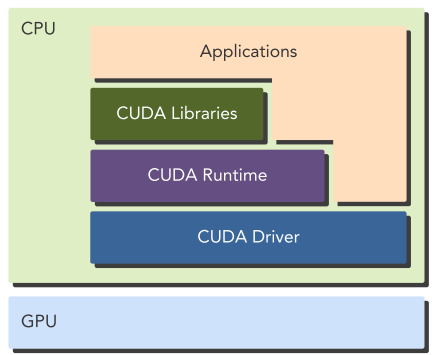
CUDA程序由Host 代码(CPU上执行)和Device 代码(GPU上执行)组成,提供了nvcc编译器在编译阶段将二者分离。Host代码是标准C代码并且之后交给C编译器,而Device代码是C-extended代码(用于并行计算的functions,称为核(kernels))则继续由nvcc进行编译,在连接(link)阶段,CUDA Runtime也被调用以用来显式操作GPU。