需求
给定一个markdown文件,其中的图片链接均来自网络,如何用python写一下脚本以实现快速将其中所有的图片从其所在的网站中下载下来。
代码示例
download_md_pics.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import requests
import re
def download_images_from_md(md_file):
with open(md_file, 'r', encoding='utf-8') as file:
content = file.read()
img_urls = re.findall('!\[.*?\]\((.*?)\)', content)
for url in img_urls:
try:
response = requests.get(url)
response.raise_for_status()
if response.status_code == 200:
filename = url.split('/')[-1]
with open(filename, 'wb') as image_file:
image_file.write(response.content)
print(f"Downloaded: {filename}")
except (requests.exceptions.RequestException, IOError) as e:
print(f"Failed to download: {url}")
print(f"Error: {e}")
md_file_path = './test.md'
download_images_from_md(md_file_path)
|
运行结果
1
| python download_md_pics.py
|
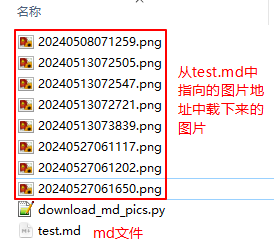
所有test.md中指向的图片链接都被下载了下来: